 |
 |
 |
 |
 |
 |
 |
|
|
|
|
|
|
|

| ECONOMIE
Economia este o stiinta sociala ce studiaza productia si desfacerea, comertul si consumul de bunuri si servicii. Potrivit definitiei date de Lionel Robbins in 1932, economia este stiinta ce studiaza modul alocarii mijloacelor rare in scopuri alternative. Deoarece are ca obiect de studiu activitatea umana, economia este o stiinta sociala. |
| StiuCum
Home » ECONOMIE
» economie generala
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analiza legaturilor intre fenomenele economico-sociale |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ANALIZA LEGATURILOR INTRE FENOMENELE ECONOMICO-SOCIALERelatia de dependenta intre doua variabile statistice se numeste legatura sau corelatie statistica. Pentru a reconstitui si previziona valorile unei variabile se poate utiliza informatia continuta in valorile unei alte variabile, cu care se afla in corelatie. O variabila Y este explicata prin variatia variabilei X, care devine explicativa. Modelarea variabilitatii unei caracteristici prin variatia unei alte caracteristici, incepe prin cuantificarea gradului de legatura dintre ele. Astfel se poate sti daca exista legatura semnificativa sau nu intre cele doua variabile. Analiza corelatiei dintre Y si X, unde Y = f(X) poate conduce la masurarea intensitatii unei legaturi functionale sau sesizarea absentei unei legaturi, atunci cand cele doua variabile sunt independente. Modelarea unei relatii intre doua variabile dependente consta in stabilirea unui model liniar sau neliniar exprimat printr-o functie analitica, care sa descrie cel mai bine aceasta relatie si care sa explice variatia lui Y, in cea mai mare masura posibila.
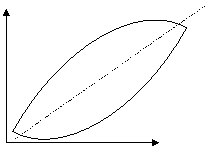
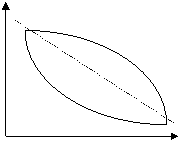
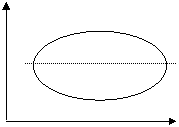
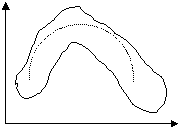
. . . . . . . . . . . . . . . . . . . . . . . . a) b)
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . .. . . . . . . . c) d) Figura 6.1. Forme de legaturi intre variabile In graficul din Figura 6.1.a), legatura dintre X si Y este inversa: pe masura ce X creste, Y scade; in acest caz, este indicat modelul liniar, fapt verificat vizual prin trasarea liniei drepte intrerupte. In graficul 6.1.b), legatura este directa: creste X, creste si Y, si se poate aproxima evolutia legaturii lor, dupa o dreapta; modelul ales poate fi cel liniar, Y = a + bX. Graficul 6.1.c) sugereaza utilizarea unui model neliniar, de exemplu o parabola: Y=a+bX+cX2. Graficul 6.1.d) arata lipsa existentei legaturii intre cele doua variabile: X si Y. Metodele de analiza a legaturilor intre fenomenele economico-sociale se impart in doua mari categorii: metode de verificare a existentei, a formei (liniara / neliniara) si a naturii (directa / inversa) legaturilor intre variabile si metode de masurare a intensitatii legaturilor. Din prima grupa de metode de verificare a existentei legaturilor dintre variabile, fac parte: metoda seriilor interdependente, care consta in extragerea de serii de date din diverse surse si analiza lor vizuala, prin compararea lor - are dezavantajul ca sesizeaza numai existenta si eventual, dar nu cu siguranta, natura unor legaturi; metoda gruparilor, care presupune sistematizarea datelor in tabele combinate dupa 2-3 caracteristici (un numar mai mare ar conduce la faramitarea colectivitatii si pierderea aspectelor esentiale) astfel: in cadrul primei caracteristici de grupare, X, pentru fiecare varianta xi, se inscriu toate variantele caracteristicii Y, cu care se afla in corelatie, eventual frecventele comune variantei xi si fiecarei variante yj, adica frecventele fij, apoi pentru fiecare varianta yj se inscriu toate variantele zk, ale variabilei Z, cu eventual, frecventele comune fijk s.a.m.d. - prezinta dezavantajul ca nu verifica decat existenta si eventual natura legaturilor; metoda grafica, care este cea mai buna dintre metodele de verificare a existentei legaturii dintre doua variabile x si y; graficul norilor de puncte ofera informatii privind existenta, forma si natura (directia) legaturii; tabelul de corelatie reprezinta o combinare a metodei gruparilor si a metodei grafice. Se alcatuieste un tabel in care, pe orizontala, in capatul coloanelor se inscriu crescator de la stanga spre dreapta variantele caracteristicii x (corespunzator axei Ox), iar pe verticala, in capatul liniilor, se inscriu descrescator de sus in jos, variantele caracteristicii y (corespunzator axei Oy). Concentrarea frecventelor din interiorul tabelului, de-a lungul primei, respectiv a celei de a doua diagonale, sugereaza existenta si natura legaturii directe sau inverse. analiza dispersionala, care prin intermediul testului Fisher poate stabili daca variabila X influenteaza semnificativ variatia caracteristicii Y, oferind doar informatii privind existenta legaturii, dar nu si despre forma sau despre natura sa; metoda balantelor, care consta in construirea unor tabele input-output (tabele cu dubla intrare) realizate pentru a surprinde legaturi intre indicatorii macroeconomici agregati; interpretarea corelatiilor se face dupa cadranele care se formeaza in aceste tabele; de exemplu ramurile economiei nationale sunt trecute atat ca ramuri producatoare, pe linii, cat si ca ramuri consumatoare, pe coloane, iar elementele de pe diagonala reprezinta consumul intern al ramurii respective, adica ceea ce se produce si se consuma in interiorul ei; tabelul de asociere, care se poate realiza pentru caracteristici cu doua variante, de natura calitativa. Variabilele numerice se pot transforma in caracteristici calitative daca cele doua variante se considera ca fiind: sub nivelul mediu / peste nivelul mediu al variabilei x, respectiv y, dupa cum se vede in Tabelul 6.1.
Tabelul 6.1. Tabelul de asociere intre variabilele x si y Grupa a doua a metodelor de masurare a intensitatii legaturilor se impart in metode parametrice si metode neparametrice. Metodele parametrice se caracterizeaza prin existenta parametrilor functiei analitice, stabiliti prin metoda regresiei, respectiv a indicatorilor de intensitate: coeficientul de corelatie, r si raportul de corelatie, R. Dintre metodele neparametrice fac parte: coeficientii de corelatie a rangurilor: Spearman si Kendall si coeficientul de asociere. Tabele de contingentaO serie bivariata poate fi descrisa fie prin enumerarea perechilor de observari (xi, yi), cand numarul unitatilor statistice inregistrate este mic: (y1, x1) (y2, x2) (y3, x3).(yi, xi).(yn, xn), fie prin prezentarea seriei sub forma de doua siruri: y1, y2, . , yi, . , yn x1, x2, . , xi, . , xn Cand numarul unitatilor statistice este mare, se pot stabili distributii de frecvente pentru cele doua variabile X si Y, datele centralizandu-se in tabele statistice. Pentru acelasi numar de grupe ale caracteristicilor X si Y, cand acestea au frecvente comune, se folosesc tabele simple, ca in Tabelul 6.2.
Tabelul 6.2. Variabilele X si Y cu frecvente comune Cand X si Y au un numar diferit de grupe, se folosesc tabele cu dubla intrare, numite tabele de contingenta, ca in Tabelul 6.3. Frecventele
fij arata numarul de
unitati statistice pentru care valorile variabilei X apartin modalitatii xi,
iar valorile variabilei Y apartin
modalitatii yj. Distributia marginala ni. a
variabilei X nu tine cont de modalitatile variabilei Y, iar distributia marginala
a lui Y, n.j nu tine
seama de modalitatile variabilei X.
Volumul total n.. reprezinta numarul
unitatilor statistice inregistrate:
Tabelul 6.3. Tabelul de contingenta Un tabel de contingenta este un tabel cu dubla intrare, cu k linii si p coloane sau k distributii conditionate ale lui X si p distributii conditionate ale lui Y. Pentru
o modalitate fixata a 323g66d caracteristicii Y,
yj, perechile (xi, fij) cu i = 1, k definesc o serie unidimensionala a variabilei X conditionata de valoarea yj, numita distributia conditionata a variabilei X.
Media conditionata a variabilei X de
varianta In mod similar, pentru o modalitate fixata xi a variabilei X, se poate stabili distributia conditionata a variabilei Y, seria unidimensionala fiind formata din sirurile (yj, fij), unde j=1,p. Se calculeaza media conditionata a lui Y de valoarea xi,
Y/ xi: dispersia conditionata a lui Y/ xi:
Considerand
numarul de grupe egal cu k, numar de
linii, In
cazul unei serii bivariate cu frecvente, graficul norilor de puncte se
construieste astfel: pe axa Ox, se reprezinta valorile lui X, iar pe axa Oy, mediile conditionate ale lui Y, Indicatorii care masoara intensitatea legaturii dintre variabilele X si Y se calculeaza tinand seama de cele trei situatii ale variabilelor X si Y: distributie fara frecvente, distributie cu frecvente comune si distributie de frecvente, proprie fiecarei variabile. Metoda regresieiAjustarea sau modelarea unei serii consta in calculul valorilor teoretice corespunzatoare valorilor empirice, observate. Tehnicile de ajustare utilizeaza cel mai adesea criteriul 'celor mai mici patrate' pentru determinarea parametrilor modelului retinut. Metoda regresiei consta
in alegerea acelei functii analitice, numita functie de regresie, care satisface cel mai bine criteriul
minimizarii patratelor abaterilor
valorilor observate de la cele teoretice aflate pe curba de ajustare: min Daca se doreste modelarea relatiei Y = f(X), atunci se considera Y ca fiind variabila dependenta, endogena, explicata, iar X, ca fiind variabila independenta, factoriala, exogena, explicativa. In cazul in care exista o singura variabila independenta X, metoda este regresia simpla, iar cand exista mai multe variabile exogene X1, X2, ,Xn, se foloseste regresia multipla, avand ca scop modelarea relatiei Y = f(X1, X2, ., Xn). Cel
mai simplu caz este ajustarea folosind functia liniara:
Rezolvand
acest sistem se obtin solutiile: Estimatorii
Parametrul
Tabela de regresieMulte produse informatice: Quattro Pro, SPSS, Excel, etc. rezolva regresia liniara simpla si regresia liniara multipla. Se declara variabila dependenta, variabila sau variabilele independente si locul pe spreadsheet (celula reprezentand coltul din stanga sus) unde se doreste obtinerea tabelei de regresie. Automat se obtine tabela de regresie care va contine indicatorii validitatii modelului, tabelul de analiza a variantei ANOVA si estimatorii parametrilor modelului liniar.
Figura 6.2. Boxa-dialog pentru procedura Regression La apelarea acestei proceduri se deschide o boxa-dialog, ca cea din Figura 6.2, formata din doua parti: prima, numita Input, referitoare la declararea blocurilor de date, pentru variabila dependenta Input Y-Range si pentru variabila sau variabilele independente, Input X Range si a doua, numita Output options, referitoare la rezultatele pe care le va contine tabela de regresie.
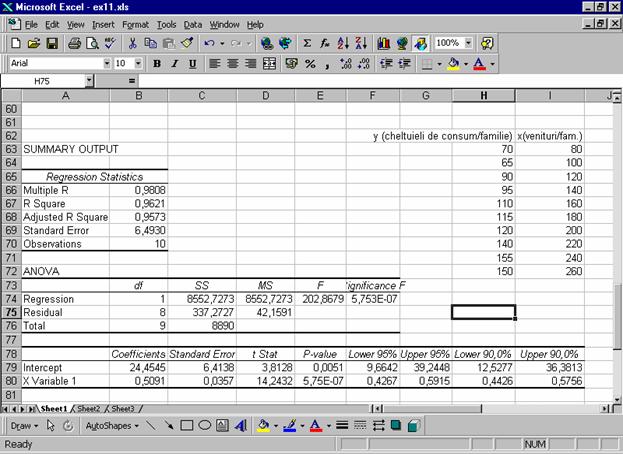
Figura 6.3. Tabela de regresie pentru variabilele x si y Interpretarea tabelei de regresie consta in analiza rezultatelor sale astfel: Multiple R, este coeficientul de corelatie multipla, in acest caz de corelatie simpla intre x si y; valoarea r = 0,98 indica o legatura puternica si directa intre cheltuielile si veniturile saptamanale. R
Square, Adjusted
R Square, este un coeficient de determinatie
corectat cu grade de libertate si are aceeasi semnificatie ca si Standard
Error este eroarea standard si arata cu cat se abat
in medie valorile observate yi,
de la valorile teoretice aflate pe dreapta de regresie, Observations este n, numarul de observari, aici n=10. ANOVA reprezinta tabelul de analiza a variantei. Pentru varianta datorata factorului x, Regression, varianta reziduala, datorata celorlalti factori neinregistrati, Residual, si varianta totala, datorata tuturor factorilor, Total, se specifica: df (degrees freedom), gradele de libertate: k - numarul de variabile explicative x (fiind regresie simpla k=1, in B74, pentru un singur factor x), n-k-1 pentru reziduuri (10-1-1=8 grade de libertate, in B75) si n-1 pentru total variatie (10-1=9, in B76); Suma df pentru Regression si Residual este egala cu df pe Total: k + (n - k - 1) = n - 1. SS, prescurtarea de la Sum Square, adica suma patratelor abaterilor, numite variante, astfel: Regression:
Residual:
Total: Intre aceste
variante exista relatia: Total=Regression+Residual,
adica MS, prescurtarea de la Modified Sum, numite sume modificate, de fapt, dispersii modificate: Regression:
Residual:
F,
testul Fisher de semnificatie globala a regresiei, in celula E74, reprezinta
raportul dintre cele doua dispersii corectate cu gradele de libertate, din
celulele D74 si D75: Significance
F, in celula F74, reprezinta pragul de
semnificatie α, de la care valoarea testului F devine semnificativa: In ultima parte a tabelei apar coeficientii modelului liniar: Intercept, fiind termenul liber, care poate sa fie zero, daca se opteaza pentru Constant is zero in boxa-dialog si coeficientii pentru fiecare variabila explicativa, in acest caz numai unul, X Variable 1. In celulele B79 si B80 sunt valorile Coefficients, iar in C79 si C80 apar abaterile standard ale coeficientilor, Standard Error, apoi in D79 si D80 sunt calculate valorile t Student, numite t Stat, ca raport intre coeficienti si abaterile lor, iar P-value, reprezinta pragul de semnificatie α, de la care valorile coeficientilor devin semnificativ diferite de 0. In E79 se citeste valoarea α = 0,0051 sau α = 0,51%, deci se poate afirma cu o probabilitate 100 - α de 99,49% ca valoarea intercept-ului este semnificativ diferita de 0. In E80, P-value pentru coeficientul variabilei x conduce la aceeasi concluzie. In plus se observa ca valoarea P-value este aceeasi cu cea din Significance F, pentru ca fiind o regresie simpla, semnificatia globala se reduce la semnificatia coeficientului variabilei explicative. In coloanele F, G, H si I, in liniile 79 si 80, tabela de regresie contine intervalele de incredere ale estimatorilor coeficientilor modelului, pentru probabilitatile de 95% si 90%. Pentru probabilitatea 95%, intervalele de incredere apar implicit; pentru probabilitatea 90%, s-a solicitat in boxa-dialog a regresiei prin marcarea in casuta Confidence Level, in care s-a declarat 90%, altfel in mod implicit in coloanele H si I, ar fi aparut aceleasi intervale ca cele din coloanele F si G, pentru 95% probabilitate. Modelul
liniar va contine estimatorii obtinuti cu acest esantion de date:
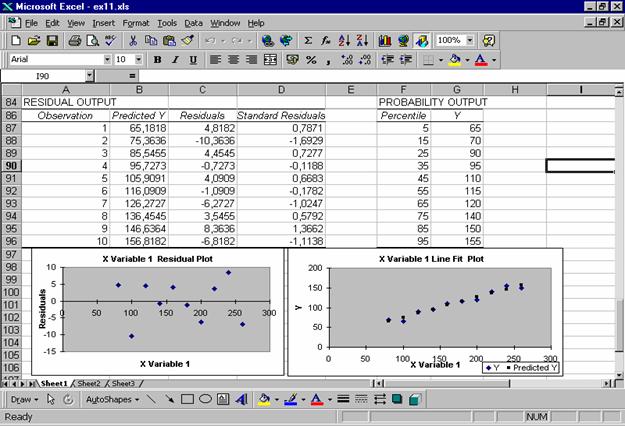
Figura 6.4. Optiuni suplimentare ale tabelei de regresie Daca in zona de Output se marcheaza optiunile pentru Residuals, in Figura 6.4 se obtin valorile teoretice prin modelul liniar estimat, in blocul de celule B87:B96 si reziduurile, ca diferente intre valorile y observate si aceste valori teoretice, estimate, in blocul C87:C96. Daca se alege in boxa-dialog si optiunea Standardized Residuals, atunci in coloana D apar automat reziduurile standardizate, care se pot obtine, altfel, prin impartirea reziduurilor la abaterea lor standard (media reziduurilor este 0). Abaterea standard este furnizata de functia STDEVP(C87:C96). Optiunile Residual Plots si Line Fit Plots conduc la cele doua grafice, care apar in Figura 6.4: primul conduce la concluzia, dupa forma norului de puncte, ca nu exista corelatie intre variabila x si reziduuri, adica modelul este bine ales, iar al doilea grafic prezinta valorile observate si cele estimate (aflate pe dreapta de regresie) ale variabilei dependente y. Normal Probability Plots conduce la rezultatele din blocul F84:G96 si un grafic corespunzator. Pentru regresia multipla in boxa-dialog a regresiei, se declara la Input X-Range, blocul variabilelor explicative, care trebuie sa fie situate in coloane adiacente, pentru a putea forma un bloc compact. Coeficientii variabilelor explicative sunt furnizati de tabela de regresie in ordinea succesiunii variabilelor explicative in blocul declarat. Ajustarea neliniaraIn cazul cand modelul este neliniar, se poate recurge la liniarizarea relatiei pentru a facilita calculul estimatorilor parametrilor modelului. Ajustarea polinomiala este mai delicata, pentru ca intervine un polinom de grad mai mare. Calculul coeficientilor de ajustare pentru functia putere: y = a xb , pot fi obtinuti printr-o ajustare
liniara, prin aplicarea functiei logaritmice celor doi membri ai relatiei: Coeficientii unei ajustari exponentiale: Y = a
bx , pot fi obtinuti prin utilizarea acelorasi
variabile transformate: Coeficientii unei ajustari parabolice pot fi obtinuti prin liniarizarea ecuatiei de
gradul doi: Coeficientul de corelatie simplaIntensitatea
legaturii dintre X si Y se masoara utilizand coeficientul de corelatie liniara, r. Coeficientul de corelatie, r, arata gradul de influenta a
variabilei X asupra variatiei
variabilei Y, si se calculeaza
astfel:
Formula
coeficientului de corelatie devine astfel: Inlocuind abaterile standard din formula lui r, se obtine formula de calcul simplificat a lui r:
Coeficientul de corelatie ia valori intre -1 ≤ r ≤ 1. Daca legatura intre X si Y este inversa, semnul lui r este negativ, daca legatura este directa, semnul este pozitiv. O valoare a lui r cat mai apropiata de ±1, arata o legatura puternica intre X si Y; o valoare apropiata de 0 arata lipsa legaturii. Interpretarea coeficientului de corelatie se face astfel: 0 £ r < 0,2 - lipsa unei legaturi; £ r < 0,5 - legatura de intensitate slaba; £ r < 0,75 - legatura de intensitate medie; £ r < 0,95 - legatura de intensitate puternica; £ r < 1 - legatura foarte puternica, aproape de tip determinist. Aprecierea intensitatii legaturii dintre doua variabile se face tinand cont de intervalul in care se incadreaza coeficientul de corelatie. In cazul cand seriile de date au distributii de frecvente comune, coeficientul de corelatie liniara simpla este: Cand seriile de date pentru variabilele X si Y au distributii proprii de frecvente, coeficientul de corelatie este:
Cand seriile de date ale
variabilelor X si Y, provin dintr-un esantion, se poate
testa semnificatia coeficientului de corelatie prin calculul unei valori: Raportul de corelatie. Coeficientul de determinatie. Un
alt indicator care masoara intensitatea legaturii intre X si Y este raportul de corelatie, R, care se calculeaza ca radical din coeficientul de determinatie, R2. R2 se obtine ca raport intre dispersia lui Y
pe seama lui X sau dispersia
explicata de model, notata
R2 arata
in ce masura modelul ales explica variatia lui Y, altfel spus, este o masura a validitatii modelului. 0 ≤ R2 < 1, cu cat este mai
apropiat de 1 cu atat modelul este mai bun. Raportul
de corelatie are semnul coeficientului de regresie,
Frecventele variabilelor X si Y, apar in formule, langa variabilele pe care le reprezinta. In cazul legaturii liniare, raportul de corelatie si coeficientul de corelatie sunt egali: R = r. Aceasta egalitate este un test al liniaritatii legaturii. In caz de inegalitate rezulta ca legatura nu este liniara si trebuie cautata o alta functie analitica pentru modelarea legaturii intre X si Y. Coeficientul de determinatie R Curba regresiei variabilei Y in functie de X, este formata de punctele care au pe abscisa diferite valori ale lui X si pe ordonata mediile conditionate ale variabilei Y/X , permitand studierea influentei lui X asupra lui Y, la nivel de medii conditionate. In cazul legaturilor neliniare, coeficientul de corelatie, r, se transforma in raport de corelatie. Daca modelul contine mai multe variabile explicative, R se numeste raport de corelatie multipla, iar r, coeficient de corelatie multipla. Functia de regresie este utila pentru previziunea variabilei Y, cunoscand valorile variabilei X. Coeficientii de corelatie a rangurilor. Coeficientul de asociere.Coeficientii de corelatie a rangurilor se utilizeaza, cand una din variabile este nenumerica, sau ambele sunt numerice, dar au un numar relativ redus de variante, cu distributii asimetrice. Variabila x se ordoneaza crescator si i se atribuie rangurile 1,2,..n, iar variabila y, primeste rangurile corespunzatoare, crescator daca legatura este directa si descrescator daca legatura este inversa. Coeficientul
de corelatie a rangurilor al lui Spearman se calculeaza dupa formula: Coeficientul de corelatie a
rangurilor al lui Kendall, se calculeaza dupa formula: Intre cei doi coeficienti exista
relatia Coeficientul de asociere se
calculeaza pe baza frecventelor stabilite intr-un tabel de asociere de forma
Tabelului 6.1, iar formula este: +1, cand arata asociere completa de sens direct, -1, asociere completa de sens invers si 0, lipsa asocierii. Exemple de utilizarea a coeficientilor de corelatie a rangurilor si a coeficientului de asociere se regasesc in exercitiile propuse si rezolvate mai jos (nr. 6). ExercitiiSe cunosc informatiile urmatoare despre evolutia traficului de marfa (tone-km) si a Venitului National (mild. lei).
a) Sa se traseze graficul corelatiei dintre cele doua variabile si sa se modeleze legatura. b) Sa se verifice semnificatia coeficientului de corelatie pentru o probabilitate de 95%. Un cercetator face afirmatia ca exista o legatura liniara intre temperatura atmosferica si vanzarile de gaze pentru incalzirea locuintelor. Pentru verificarea acestei afirmatii, el foloseste doua serii de date de la Institutul de Meteorologie.
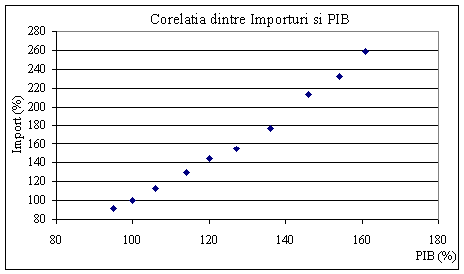
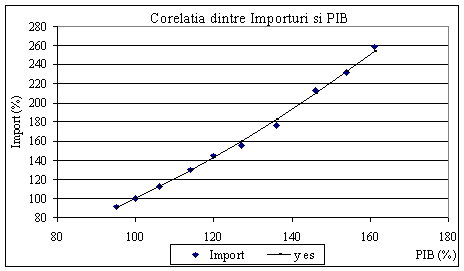
a) Sa se studieze corelatia dintre temperatura atmosferica si vanzarile de gaze pentru incalzirea locuintelor. b) Sa se verifice semnificatia coeficientului de corelatie pentru probabilitatea 90%. c) Stiind ca in septembrie, anul urmator, temperatura medie va fi 10˚ C, care este valoare previzionata pentru vanzarea de gaz obtinuta prin modelul liniar stabilit inainte. d) Dar previziunea pentru luna ianuarie anul urmator, cand temperatura medie va fi de 0˚C? Tabelul urmator arata evolutia a doi indicatori macroeconomici exprimati sub forma de indici de modificare, fata de baza aleasa ca fiind perioada a 2-a:
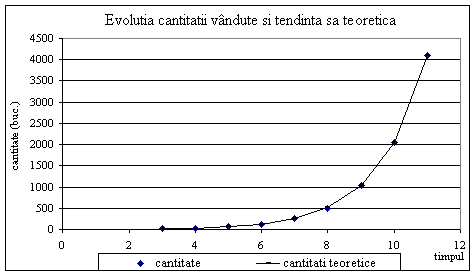
Se propune o ajustare a importurilor (Y) in raport cu PIB (X), prin functia putere: Y = a Xb Se propune prezentarea evolutiei in raport cu timpul, t, a cantitatii vandute, Q, dintr-un produs, intr-un mediu economic favorabil, printr-o relatie de forma: Q = abt . Pentru determinarea valorilor a si b se dispune de urmatoarele date:
Sa se calculeze valorile teoretice prin modelul ales. Despre un esantion de 435 de muncitori se cunosc date privind vechimea si timpul mediu nelucrat pe un schimb.
a) Sa se calculeze timpul mediu nelucrat pe grupe de vechime si pe total colectivitate; sa se arate daca aceste marimi sunt reprezentative. b) Sa se arate daca vechimea reprezinta un factor semnificativ pentru variatia timpului nelucrat, folosind testul Fisher si coeficientul de determinatie. c) Sa se aplice metoda regresiei pentru alegerea unui model adecvat. d) Sa se calculeze coeficientul de corelatie si raportul de corelatie intre vechimea in munca si timpul mediu nelucrat pe un schimb. Pentru 10 familii s-au inregistrat veniturile xi si cheltuielile de consum, yi, in mii lei pe saptamana. Veniturile si cheltuielile difera in functie de numarul de membri salariati si nesalariati ai unei familii, de educatie si obiceiuri, etc.: (mii lei)
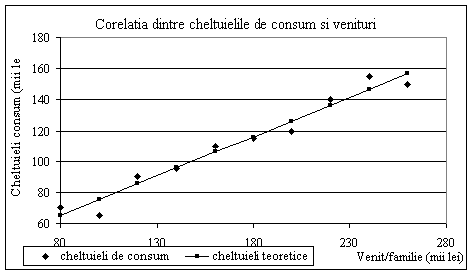
a) Sa se utilizeze metoda regresiei in analiza legaturii dintre cheltuielile de consum si venituri. b) Sa se calculeze coeficientul de corelatie, raportul de corelatie si coeficientul de determinatie al legaturii dintre cele doua variabile. c) Sa se traseze graficul variabilei cheltuieli de consum (y) in functie de venituri (x), si al valorilor teoretice situate pe curba de regresie. d) Sa se utilizeze tabelul de asociere si sa se calculeze coeficientul de asociere. e) Sa se masoare intensitatea legaturii dintre x si y, utilizand metodele neparametrice, coeficientii de corelatie a rangurilor: Spearman si Kendall. Fie ri, coeficientul de corelatie
intre N perechi Obs: Operatiile axi , xi + b si axi + b sunt cunoscute ca fiind: schimbarea scalei, a originii, respectiv, schimbarea ambelor. Pe baza a 10 observari s-au obtinut rezultatele: åyi åxi åxi yi åxi2 åyi 2 = 132.100 si r = 0,9758. Care este efectul inlocuirii a doua observari din situatia (1) cu cele din situatia (2) si care este noul coeficient de corelatie ? Daca r, coeficientul de corelatie intre N perechi de valori (xi, yi) este pozitiv, atunci inseamna ca: a) r intre (-xi, -yi) este de asemenea pozitiv; b) r intre (-xi, yi) si cel intre (xi, - yi) poate fi fie pozitiv, fie negativ; c) Atat coeficientul de regresie bxy, cat si byx, sunt pozitivi, unde byx este coeficientul de regresie pentru y = f(x) si bxy este coeficientul regresiei x = f(y). Sa se argumenteze raspunsul: fals sau adevarat, pentru afirmatiile de mai sus. Daca x1, x2 si x3 sunt variabile necorelate, fiecare avand aceeasi abatere standard, s, sa se arate ca valoarea coeficientului de corelatie al variabilelor x1 + x2 si x2 + x3 este 1/2. De ce coeficientul de corelatie nu este 0? Sa
se realizeze o regresie pe variabile standardizate: Rezolvari
Figura 6.5. Corelatia dintre traficul de marfa si venitul national Tabelele de regresie prezentate mai jos sunt obtinute cu ajutorul a doua produse informatice: Quattro Pro si Excel, in Tabelele 7.4, respectiv 7.5.
Tabelul 6.4. Tabela de regresie din Quattro Pro
Tabelul 6.5. Tabela de regresie din Excel
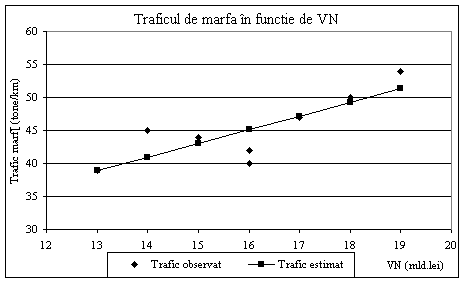
Figura 6.6. Corelatia liniara dintre traficul de marfa si venitul national 1b) Coeficientul de corelatie r este valoarea Multiple R din tabela de regresie, r=0,815. Semnificatia coeficientului de corelatie se testeaza cu
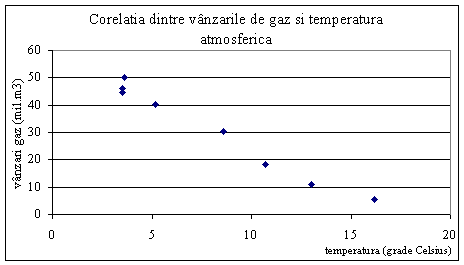
ratia Student, obtinuta prin formula Cum t > ta 6 grade de libertate , se considera r ca fiind semnificativ diferit de zero, pentru a 2a) Graficul seriilor: volumul vanzarilor de gaz pe ordonata si temperatura pe abscisa, arata un nor de puncte avand un aspect liniar. Legatura este liniara si inversa, pe masura ce creste temperatura atmosferica, scade volumul vanzarilor de gaz, dupa cum se vede in Figura 6.7.
Tabelul 6.6. Calculul parametrilor modelului de regresie liniara simpla Ecuatia de regresie este: 2b) Coeficientul de corelatie indica o legatura puternica, de sens invers, r = -0,9878 Valoarea t = 15,57 > ta tabelar, care reprezinta valoarea teoretica a ratiei Student. Pentru a = 10% aceasta valoare este ta 6 grade de libertate = 1,943. Coeficientul de corelatie este semnificativ diferit de zero. 2c) Pentru
luna septembrie a anului urmator 2d) Nici unul din raspunsuri nu este convenabil; un model nu este aplicabil decat in intervalul de valori al variabilei explicative, observate in mod real. Dupa liniarizare: ln(y) = ln(a) + b ln(x), se rezolva ca
o regresie liniara simpla:
Tabela de regresie simplificata (mai restransa) este furnizata de Quattro Pro, in Tabelul 6.7, pe baza datelor din Tabelul 6.8, declarandu-se ca variabila dependenta, ln(y) si ca variabila independenta ln(x). Coeficientul b este aproximativ 1,95.
Tabelul 6.7. Tabela de regresie simpla Tabelul 6.8 cuprinde valorile
teoretice calculate si prin modelul liniar si apoi antilogaritmarea valorilor
pentru obtinerea Coeficientul
a se obtine din a*, astfel
Tabelul 6.8. Datele observate, transformate si ajustate
Valorile
Relatia y = abx se liniarizeaza prin logaritmare: ln(y) = ln(a) + x ln(b); se realizeaza regresia liniara, declarandu-se ca variabila dependenta ln(y) si ca variabila dependenta x, variabila t, timpul. In Tabelul 6.9 sunt extrase cele mai importante informatii din tabela de regresie furnizata de Excel. Antilogaritmand
ln(a) si ln(b) se obtin estimatorii a
= 2,0077 si b = 1,9998, deci relatia se poate scrie
sub forma
Tabelul 6.9. Calculul parametrilor modelului liniar Datele observate si cele teoretice sunt prezentate in graficul din Figura 6.10, indicand clar o evolutie neliniara.
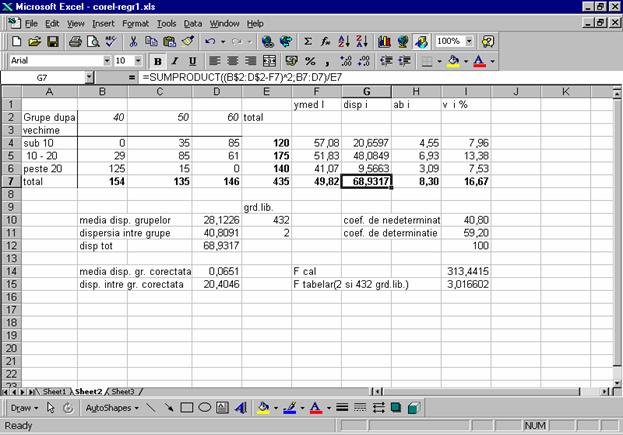
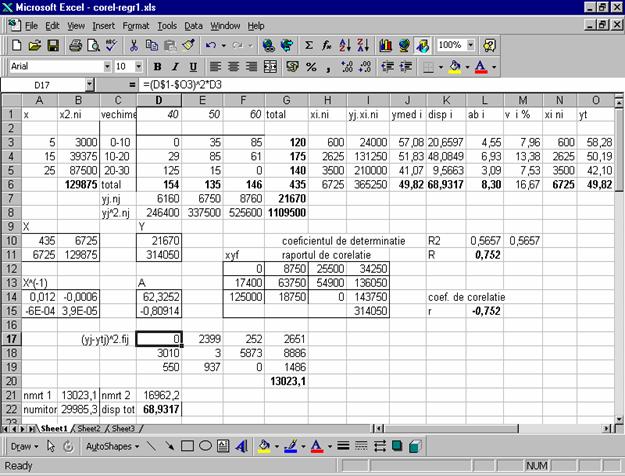
5a) Tabelul cu datele centralizate pe grupe de vechime si timpul nelucrat in minute se afla in blocul de celule A2:E7, in Figura 6.11. In coloana E se afla numarul de muncitori pe grupe de vechime, caracteristica x, numita si distributia marginala a variabilei x, iar pe linia 7, se afla distributia marginala a caracteristicii y, totalul muncitorilor pe variante de timp nelucrat pe un schimb (valorile bold-uite).
Figura 6.11. Analiza dispersionala Se observa ca valorile mediilor pe
grupe scad pe masura ce creste vechimea in munca; muncitorii mai experimentati
pierd mai putine minute in timpul procesului tehnologic. Cei mai tineri se
situeaza aproape de varianta maxima a timpului pierdut, cei cu vechimea intre
10 si 20 de ani sunt mai aproape de varianta de mijloc a caracteristicii y, iar cei mai in varsta se situeaza in
jurul primei variante, fapt care se poate observa pentru fiecare grupa, privind
concentrarea frecventelor mari in jurul variantelor respective.In blocul G4:G7,
sunt calculate dispersiile de grupa, respectiv dispersia colectivitatii totale,
5b) Pentru a testa daca variabila x este semnificativa pentru variatia caracteristicii y, se calculeaza testul Fisher, ca raport intre dispersia dintre grupe si media dispersiilor de grupa, ambele corectate cu gradele de libertate corespunzatoare. Valoarea testului Fisher din celula I14 este cu mult mai mare decat valoarea sa teoretica pentru gradele de libertate din celulele E11 si E10, si pragul de semnificatie, α=5%, fapt ce demonstreaza ca intr-adevar factorul de grupare, vechimea in munca este semnificativ pentru variatia timpului nelucrat. Valoarea teoretica a testului Fisher din celula I15 s-a obtinut cu functia =FINV(0,05;2;432). In
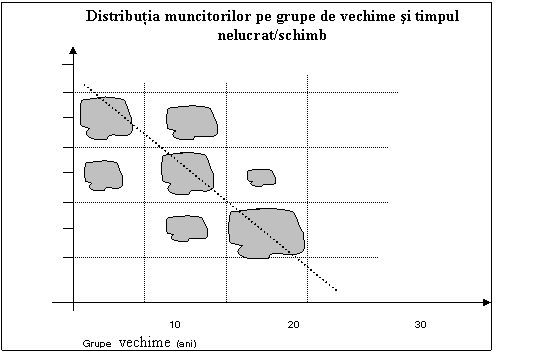
celula D10 din Figura 6.11, se afla media dispersiilor de grupa, 5c) Modelul liniar este sugerat de reprezentarea grafica din Figura 6.12, unde norii de culoare gri reprezinta numarul de muncitori (puncte) situati in grupele corespunzatoare dupa vechime si timpul neclucrat intr-un schimb.
70
In
Figura 6.13, in celulele A10:B11, se afla matricea X, cu termenii: n din celula G6,
In blocul A14:B15 este calculata inversa
matricei X, cu functia MINVERSE, apelata cu iconita f*. Se selecteaza intai locul unde se va depune rezultatul, adica
matricea inversata, deci 2 linii x 2 coloane = 4 celule. Apoi se apeleaza
functia, se declara matricea X; in Formula
Bar apare si
pentru a obtine rezultatul se apasa simultan pe trei taste
<Ctrl/Shift/Enter>. La eliberarea tastelor, in blocul selectat va apare
rezultatul. Inmultirea X-1Y are ca rezultat vectorul A, de doua
elemente. Se selecteaza intai blocul D14:D15, care va contine rezultatul, apoi
se apeleaza functia MMULT, pentru inmultirea a doua masive, se declara in
ordine intai blocul care contine matricea X-1, apoi blocul care
contine vectorul Y, se apasa simultan tastele <Ctrl/Shift/Enter> si se
obtin parametrii modelului liniar. In caz de esec se reia boxa-dialog a
functiei MMULT, apasand pe semnul "=",
din fata casetei Formula Bar, care
inseamna Edit Formula, si se apasa
din nou simultan tastele <Ctrl/Shift/Enter>. Modelul liniar este In
blocul O3:O5 s-au calculat valorile teoretice ale timpului mediul nelucrat pe
grupe de vechime, cu formula =$D$14+$D$15*A3 scrisa in O3 si apoi copiata pentru celelalte doua
grupe. Aceste valori teoretice corespund mediilor de grupa calculate in blocul
J3:J5. Media generala din J6,
Numitorul se afla in celula B22, calculat cu formula =SUMPRODUCT((D1:F1-J6)^2;D6:F6). Numaratorul
de la prima formula Coeficientul de determinatie obtinut
dupa formula a doua, in celula M10, utilizeaza acelasi numitor din celula B22,
iar numaratorul Pentru a obtine raportul de corelatie se extrage radical din coeficientul de determinatie, si se obtine in L11, valoarea R=0,752, care indica o legatura de intensitate mare intre cele doua variabile, vechimea in munca si timpul nelucrat, dar de sens invers, pentru ca raportul de corelatie are semnul coeficientului de regresie, care este negativ si atunci R= -0,752. Se calculeaza coeficientul de corelatie liniara, prin formula de calcul simplificat a lui r; se cunosc toti termenii, din calculele anterioare efectuate la obtinerea parametrilor modelului liniar: 6 a, b)
Tabelul 6.10. Valorile teoretice ale variabilei y Ecuatia de regresie este: yi = 24,45 + 0,51xi + ei . Tabela de regresie este obtinuta cu ajutorul produsului Excel.
Tabelul 6.11. Tabela de regresie obtinuta in Excel Coeficientul de determinatie se citeste din tabela de regresie R Square, 96,21%, dovedeste ca modelul liniar este bine ales pentru modelarea variatiei variabilei y. Coeficientul de corelatie este egal cu raportul de corelatie in cazul legaturii liniare si se citeste din tabela de regresie din rubrica Multiple R, 0,9808 este o valoare apropiata de 1, care arata legatura puternica de dependenta intre x si y. 6 c)
6
d) Se stabilesc mediile:
Tabelul 6.12. Tabelul de asociere al variabilelor x si y Coeficientul de asociere este 1. 6 e) Coeficientul de corelatie a rangurilor al lui Spearman
Tabelul 6.13. Calculul coeficientului lui Spearman Coeficientul de corelatie a rangurilor al lui Kendall
Tabelul 6.14. Calculul coeficientului lui Kendall Valorile apropiate de 1, ale ambilor coeficienti de corelatie a rangurilor, caracterizeaza o legatura puternica, intre cele doua variabile x si y. Coeficientul lui Kendall este mai mic decat cel al lui Spearman. Formula pentru coeficientul de corelatie intre variabilele y si x este: Una din proprietatile lui r este ca rxy = ryx , adica r este simetric. Daca se
modifica variabilele x in x* si y in y*, unde x*i = axi +
b si y*i = cyi
+ d, unde a, c > 0 , iar b si d
sunt constante, atunci exista proprietatea schimbarea scalei: x*i = axi ; y*i = cyi .
schimbarea originii: x*i = xi + b si y*i = yi + d ,
Observarile (1) se inlocuiesc cu (2):
Coeficientul de corelatie scade, pentru ca in situatia (2) fata de (1). La prima observare, x, scade cu 10 unitati, si y scade tot cu 10 unitati. La a doua observare, x scade cu 10 unitati, iar y in loc scada la fel, creste cu 10 unitati, ceea ce afecteaza r, in sensul diminuarii lui.
9 b) Fals. r-x,y< 0 , rx,-y < 0
9 c) Adevarat. rxy > 0, rezulta ca intre x si y este legatura directa: cov(x, y) > 0. y = f(x) x =f(y) 10) s s s s ; rx1,x2 = 0 ; rx1,x3 = 0 ; rx2,x3 = 0 . Coeficientul de corelatie intre x1 + x2 si x2 + x3 nu poate fi 0, pentru ca rx2,x2 = 1.
11)
O variabila este standardizata, daca se exprima in termeni de abateri fata de
media sa (schimbarea originii; centrarea fata de medie) si se imparte la
abaterea sa standard (schimbarea scalei). O variabila standardizata are media 0
si dispersia 1. Coeficientul de regresie din modelul
Regresia
dintre variabilele standardizate (implica atat schimbarea originii, cat si a
scalei) are ca rezultat obtinerea coeficientului de regresie egal cu
coeficientul de corelatie dintre variabilele x si y. Coeficientul de
corelatie dintre variabilele standardizate
Intre
coeficientul de corelatie r si
coeficientul de regresie exista relatia: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Politica de confidentialitate
|
Despre economie generala |
||||||||||
Stiu si altele ... |
||||||||||
|
||||||||||
 ,
iar dispersia conditionata a lui X/
,
iar dispersia conditionata a lui X/ ,
i = 1, k ; j = fixat.
,
i = 1, k ; j = fixat.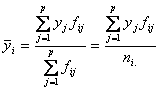 ,
, ,
j = 1, p ; i = fixat.
,
j = 1, p ; i = fixat.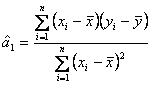 si
si 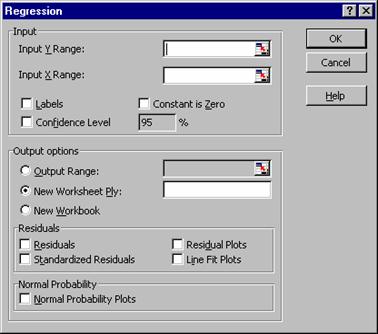
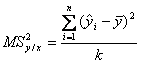
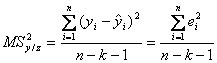
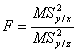 .
.
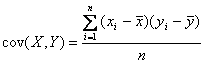 ,
iar
,
iar .
.
 .
.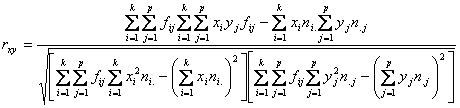
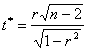 .
Aceasta valoare calculata se compara cu o valoare teoretica din tabelul
repartitiei Student, corespunzatoare unui anumit prag de semnificatie fixat,
.
Aceasta valoare calculata se compara cu o valoare teoretica din tabelul
repartitiei Student, corespunzatoare unui anumit prag de semnificatie fixat, 
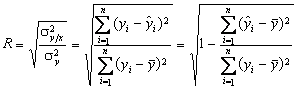 .
.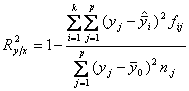 sau
sau  .
.
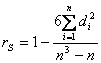 ,
unde
,
unde 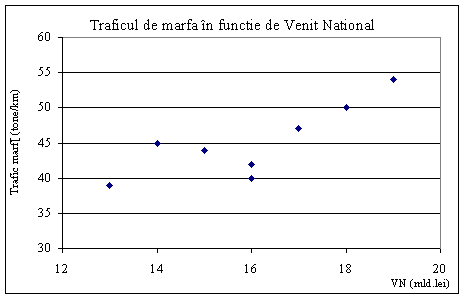
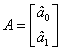

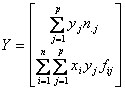
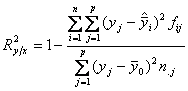
 .
.
 .
.
 .
.
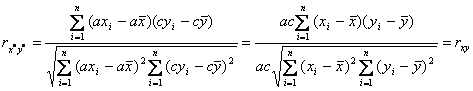
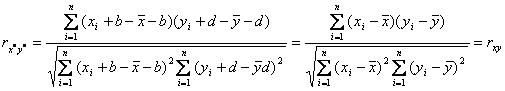
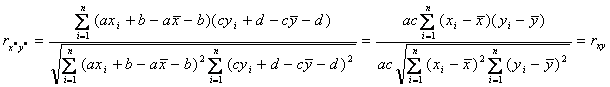
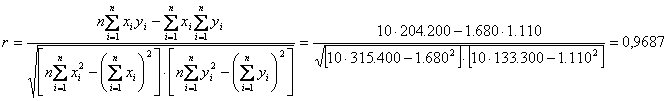






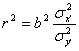 .
Cum raportul dispersiilor celor doua variabile standardizate este 1, rezulta
egalitatea r = b.
.
Cum raportul dispersiilor celor doua variabile standardizate este 1, rezulta
egalitatea r = b.